MSU Curriculum Maps (Data Science Capstone)
Pipeline for transforming university curriculum data into prerequisite networks for structural analysis.
Python
Julia
CurricularAnalytics
More details
Problem
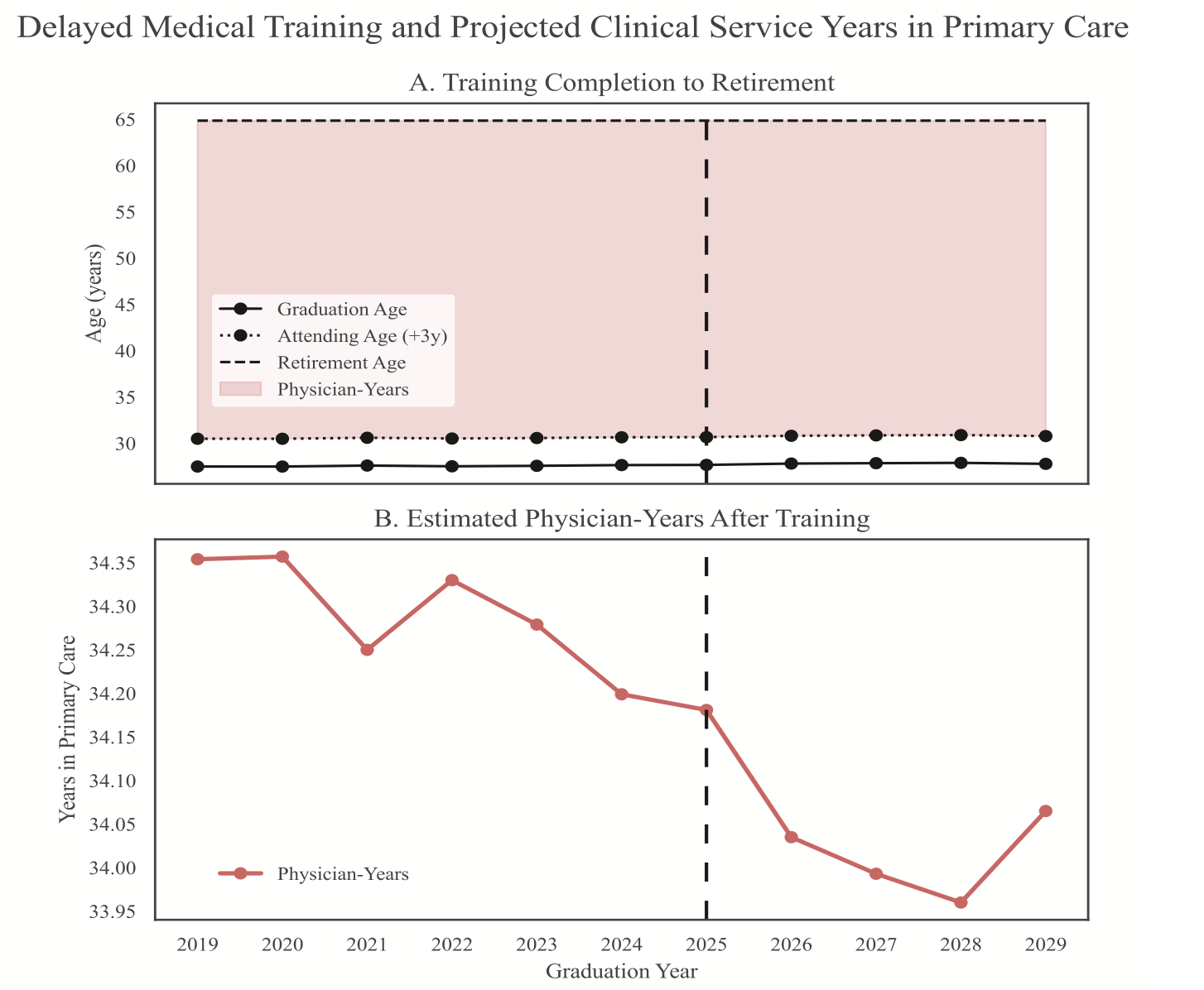
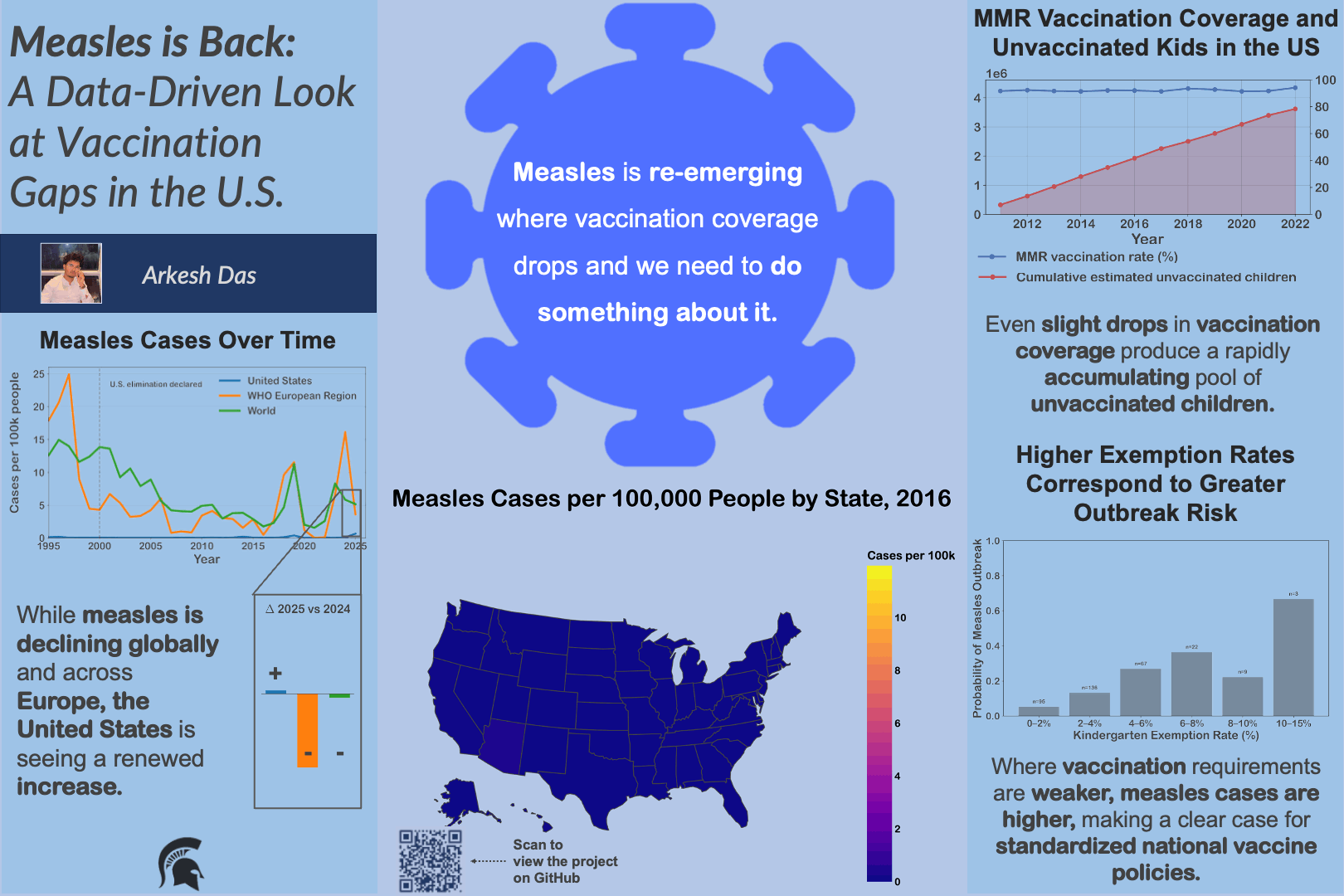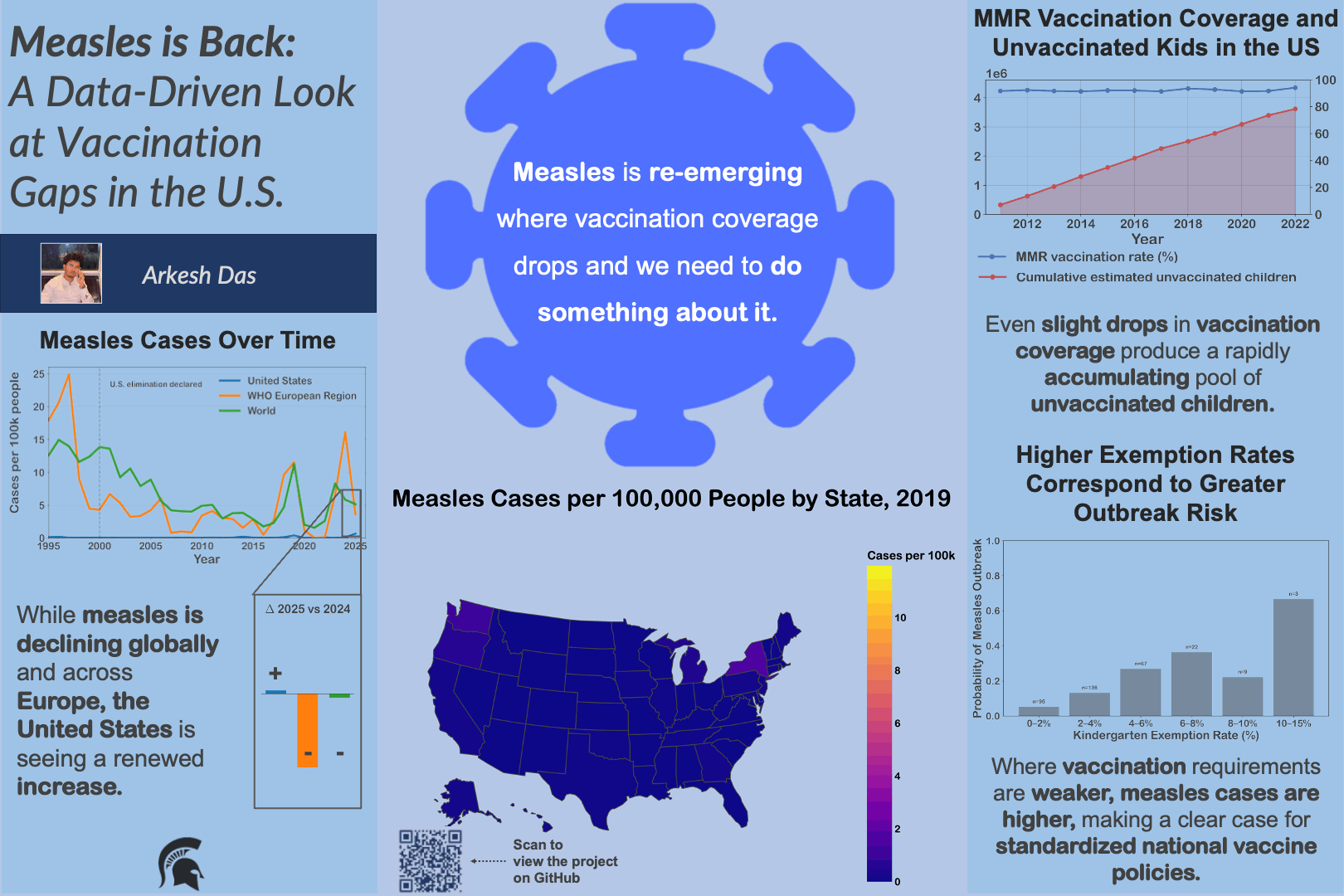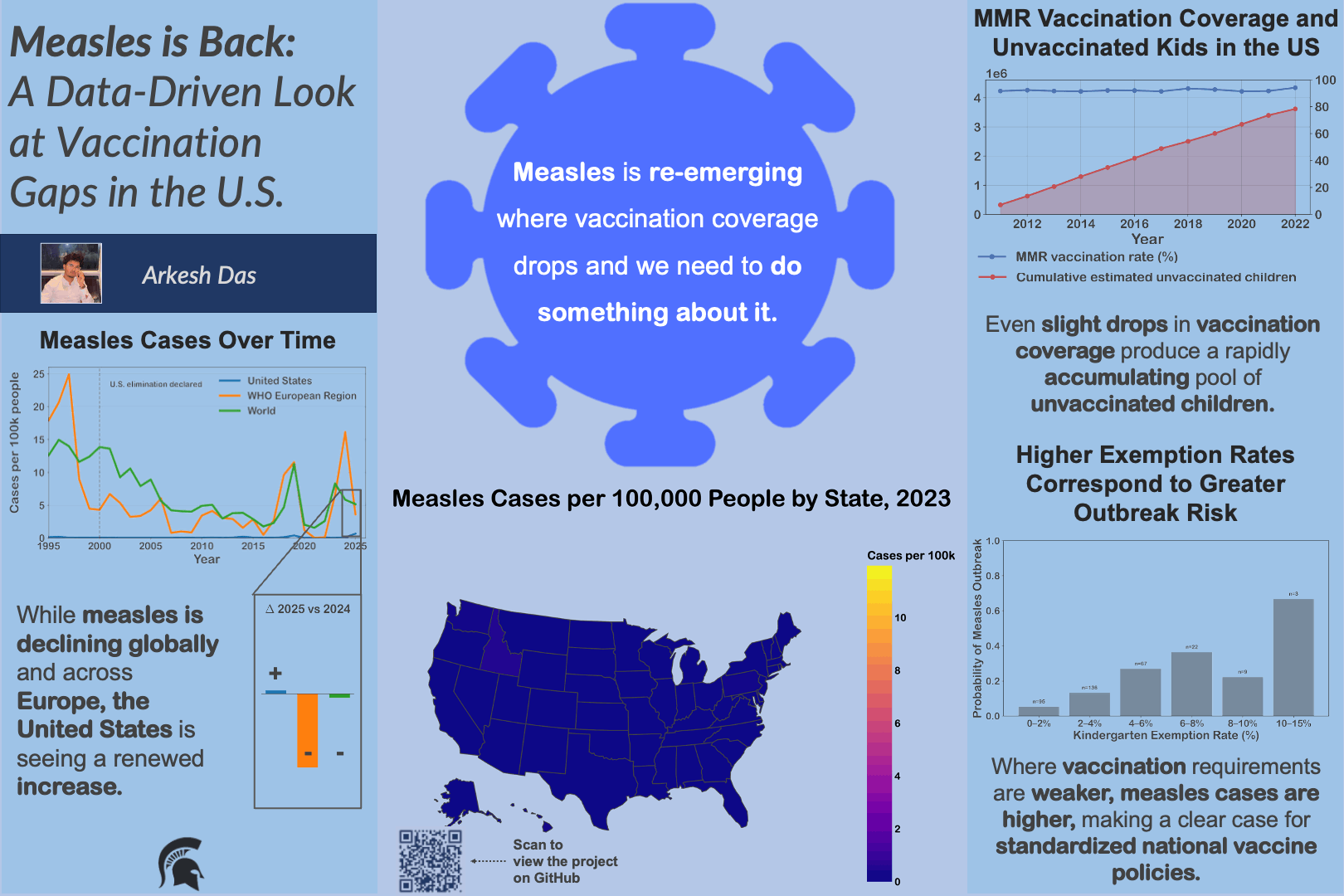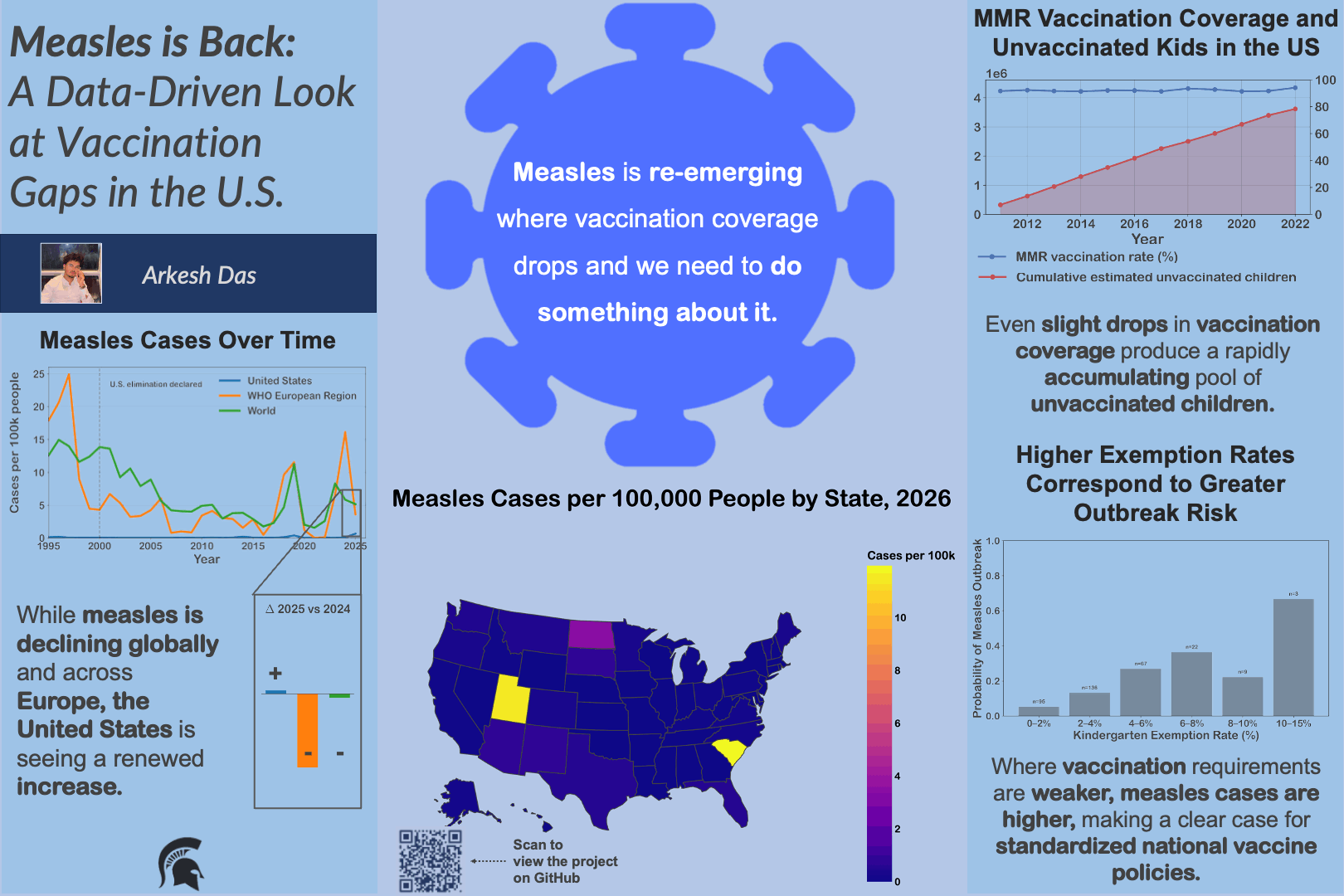
University curricula are difficult to analyze due to inconsistent data formats and complex prerequisite structures, limiting data-informed curriculum design.
Approach
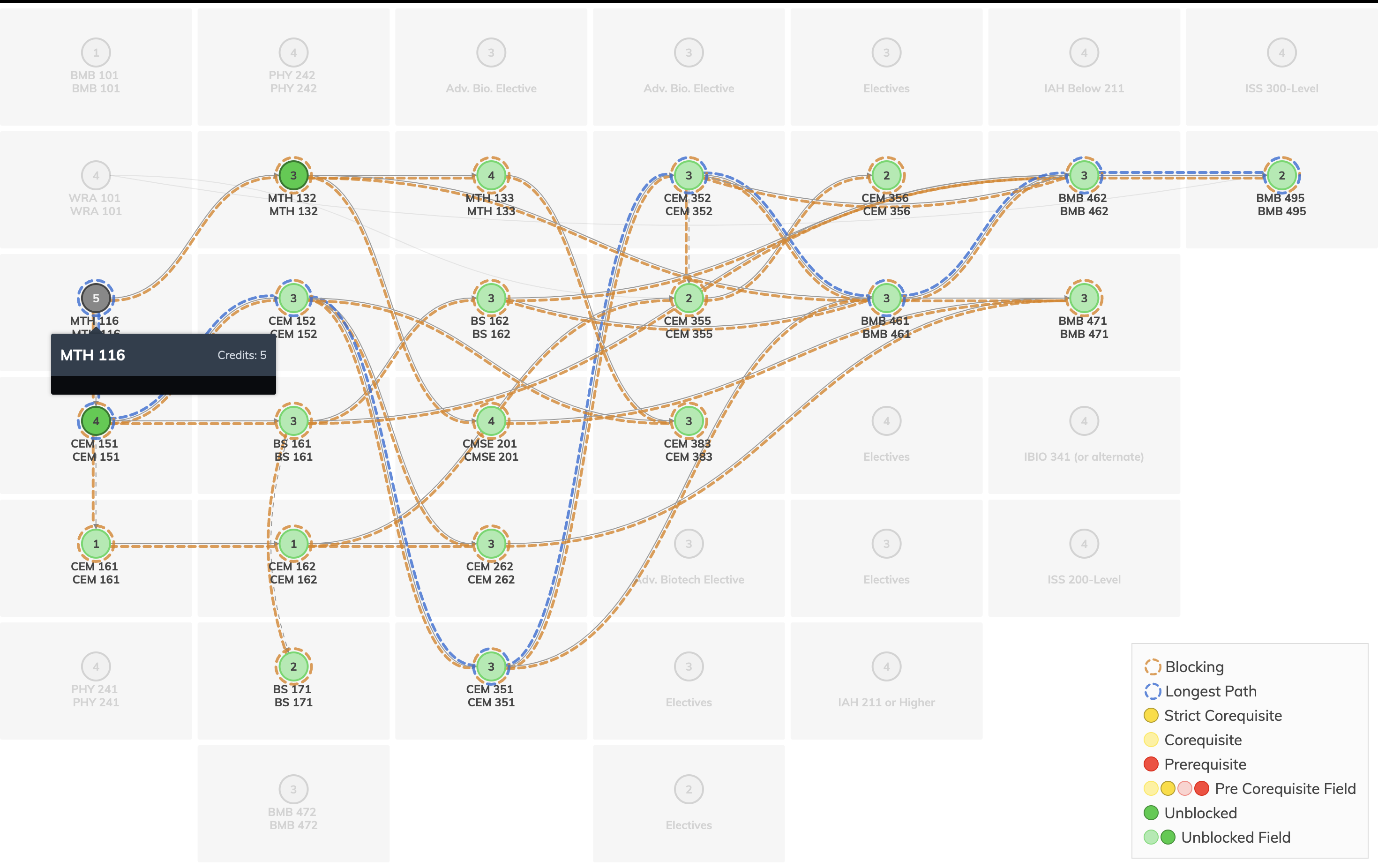
Built a reproducible pipeline to clean registrar and major requirement data, convert it into structured prerequisite graphs, and compute metrics such as blocking factor and delay factor.
Results & Impact
Enabled analysis of curriculum complexity and bottlenecks, providing a foundation for data-driven curriculum design and future institutional tools.